



The usage of massive language models (LLMs) may be appealing to enterprises looking to invest in AI and LLM modes given the current media excitement, but it is not actually possible. Yes, these models have shown incredible results on a wide range of natural language processing (NLP) tasks, but they also have several drawbacks that restrict their usability and scalability in real-world settings. In this article, we highlight why large LLMs might fail to get wide success in enterprises and why smaller, but more specialized, models are the ideal way to deploy AI in organizations.
The Challenges of Big Language Models
One of the main challenges of big LLMs is their enormous size and computational cost. These models require hundreds of billions of parameters and thousands of GPUs to train and fine-tune, making them inaccessible to most researchers and practitioners. Large-scale models consume a lot of energy and generate a lot of carbon emissions, raising ethical and environmental concerns, and may develop their own bias towards a language, culture, or ethnicity.
LLMs are trained on large and diverse textual datasets that cover a broad range of topics and domains. This makes them good at performing many generic tasks, but not great at any specific domain oriented topic. Moreover, LLMs are not easily adaptable or fine-tunable to new domains or tasks that require specialized knowledge or skills. The high impact on LLMs in industry sectors opens questions which aren’t answered by large models, like: How can we use an LLM to diagnose a rare medical condition or write a legal contract? How can we modify an LLM to suit the needs and preferences of a particular user or audience? Can we even use ChatGPT to file our taxes and prepare audits? The answer is always, not really. At least not yet.
Environmental impact
The largest and most powerful LLM available from OpenAI and BingAI, DaVinci, has 175 billion parameters and was initially trained on 45TB of text data. It costs about 6 FLOPs per parameter to train on one token, which means that training DaVinci on its entire dataset would cost about 5.25 x 10^20 FLOPs. That is equivalent to running a single NVIDIA Tesla V100 GPU for about 3.3 million years!
Inference is also expensive, as it costs 1 to 2 FLOPs per parameter to infer on one token, which means that generating a sentence of 10 words with DaVinci would cost about 17.5 to 35 billion FLOPs. That is equivalent to running a single NVIDIA Tesla V100 GPU for about 0.01 to 0.02 seconds! Imagine what power a midsize company needs to have a full working GPT3 model, which is continuously trained on dynamic data points, like chats, customer service, financial transactions, patients data, manufacturing data from robots etc. On top, the GPT-3 training consumed approximately 700k liters of water [1], and round about 500MWh up to 3GWh electricity[2].
Side note: OpenAI’s CEO Sam Altman has mentioned that the processing costs for GPT-4, the successor of GPT-3, alone was over $100 million. That blows every budget, not to mention CO2 certificates and energy usage in ESG reports.
Benefits of Distributed Data Processing for enterprise LLM
The solution to these challenges is to use smaller, but specialized models that are tailored to specific domains and tasks combined with distributed (federated) data processing. These models can leverage domain-specific data and knowledge to achieve higher accuracy and efficiency than big LLMs. And, more important, these models can be more transparent and explainable, allowing users to trust and control them better. The user has control over the data used to train these models, makes sure that no IP is exposed and, used in a correct way, reduces generative introduced bias.
Distributed data processing is a strong technology for unlocking the full potential of big data analytics, AI, ML, LLM, and data analytics in general. Businesses can deal with increasing data velocity and process massive volumes of data quicker and more effectively than ever before by implementing distributed computing. Implementing federated technology enables businesses and organizations to gain timely and precise insights from all their often distributed data, allowing them to make better decisions and increase their productivity. Federated data processing also reduces the costs associated with traditional computer systems, be it hardware acquisition and maintenance, data center management, cloud costs - and can even reduce cloud computing overspend.
How to Choose The Right Distributed Computing Platform for Your Needs
Creating smaller, more specialized models is not easy. It requires a lot of data engineering and model engineering efforts to collect, preprocess, annotate, and train data for each domain and task. It also requires a lot of infrastructure, processing power and orchestration to manage multiple models and data sources. That data is mostly massively distributed, over dozens totally different data systems, be it databases, data lakes or other big data silos. As when that is not enough, the access is mostly tricky, at best. And if that problem is solved, data regulations kicking in, some data is even not allowed to be moved out of a specialized premise.
And here’s where Blossom Sky comes in to help enterprises make the most of AI, ML, and data analytics. Blossom Sky is our groundbreaking product that helps organizations to train their LLM models on diverse and distributed data facilities. It provides a platform for smaller but specialized LLM models, which can be trained simultaneously and accurately. With the help of Blossom Sky, organizations can easily manage their data in an efficient way and also have access to the latest advancements in AI technology. Blossom Sky not only helps organizations to save time and money but also allows them to get better results from their training models.
Advantages of Implementing small LLMs in enterprises and organizations
Smaller, but specialized models are AI models that are trained and fine-tuned on smaller amounts of data that are specific to a certain domain or task. For example, a smaller model may be trained on legal documents to generate legal texts, or on medical records to generate medical reports, or on tax regulations to create the next tax declaration at the right time with the most accurate filing ever. Some of the advantages of smaller, but specialized models are:
- They require less data and computing resources to train and fine-tune. Smaller models have fewer parameters and use less data than big LLM models. This reduces the cost and complexity of training and fine-tuning them. Moreover, the data used for training smaller models is more relevant and reliable for the target domain or task, which improves the quality and accuracy of the generated texts.
- They are domain-specific and task-oriented. Smaller models are optimized for a specific domain or task, which means that they have more knowledge and context to generate texts that are appropriate and useful for that domain or task. For example, a smaller model trained on legal documents may be able to generate a legal document with the same level of precision and expertise as a human expert.
- They are more interpretable and controllable. Smaller models are more transparent and explainable than big LLM models. This makes it easier to understand how they function, what they know, and what they don't know. It also makes controlling or modifying their results easier based on personal demands or preferences. For example, a smaller model trained on medical records may provide some evidence or reasoning for its generated medical report.
DataBloom’s Blueprint for a modern AI Center of Excellence
Traditional data engines struggle with enormous amounts of data dispersed across various sources when searching or processing analytical queries, ML or AI models. This is where Blossom Sky comes in. Blossom Sky eliminates the need for unnecessary data copying and moving, reduces the cost of data management and ETL processes. Blossom Sky links directly to available data processing platforms and databases, utilizing APIs and programmable APIs. Our technology returns in a single query results from Hadoop, S3, Snowflake, ADLS, Spark, Delta Lakes, Lake Houses, BigQuery, Flink, PostgreSQL, and many other data platforms. Blossom Sky offers a highly efficient, parallelized execution method that accelerates queries while reducing time to insight to minutes.
Blossom Sky enables users to easily build and train smaller, but specialized models for various domains and tasks over multiple data sources, mostly simultaneously. Blossom Sky leverages the power of big LLMs as a starting point, but allows users to customize them with their own data and knowledge. Blossom Sky also supports simultaneous training of multiple LLMs on different, independent data sources, enabling users to create diverse and robust models that can handle different scenarios.
With Blossom Sky, users can benefit from the best of both worlds: the generality and scalability of LLMs and the specificity and interpretability of smaller, but specialized models. Blossom future-proofs any analytics architecture by separating data storage and processing, allowing it to better use best-of-breed BI apps now and in future. Blossom also delivers the efficiency and flexibility to expedite time to insight with high concurrency through federated cost-based query optimization.
LLM training in practise with Blossom Sky
Let’s use an example: a finance institution wants to build an LLM-based credit scoring system combined with an anti-money-laundering model to prevent the misuse of loans for criminal activities. This pipeline involves multiple data silos operated by different teams in multiple, mostly international, locations. In a traditional data architecture, typically involving multiple data silos, databases or separate data lakes, the data architecture might look like in this picture:
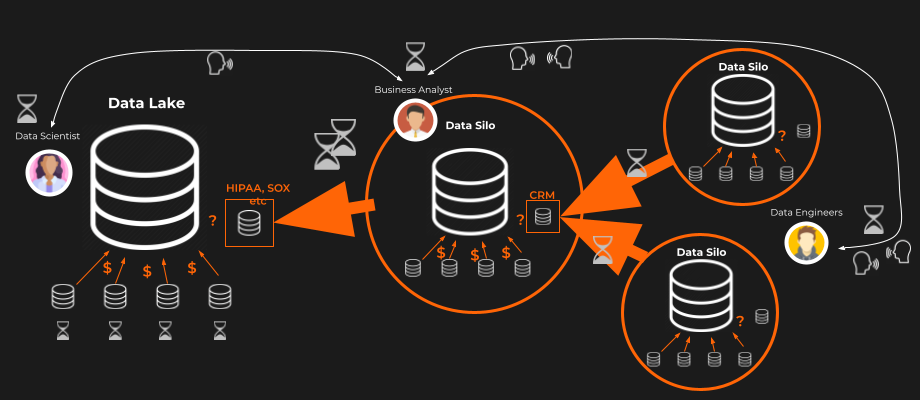
The Blossom Sky Advantage
Users of Blossom Sky can query data from numerous sources for cross-cluster execution using features such as cost-based query optimization, automatic data regulation (in development), and data processing and query federation. This removes the need to write sophisticated code, queries, and data integration processes, which introduces several potential for query failure and hazards in order to get the same outcomes.
With Blossom Sky, the same approach looks like this picture:
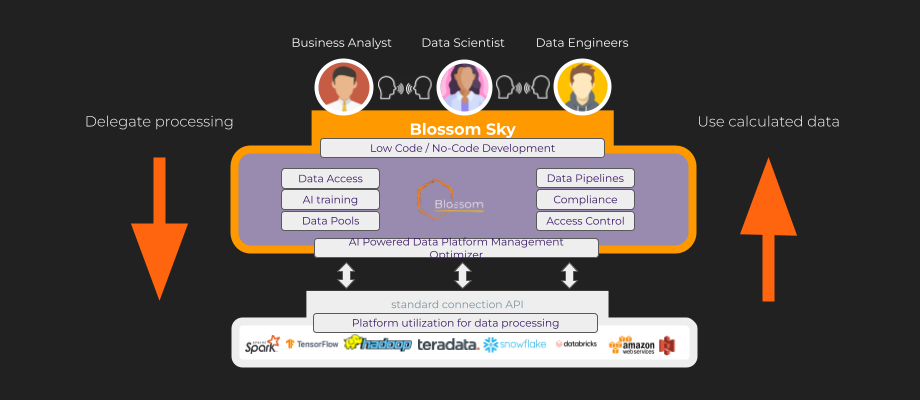
Blossom Sky users have the unfair benefit of not caring about data architecture, or even what query language they must use. Blossom Sky users access and analyze more complete data using their existing tools and knowledge based on their preferred coding language, such as Java, SQL, or Python. We reduce the intricacies of data engines, processing, and query language with our low-code UI. Blossom Sky users may focus on their duties while utilizing tools they are familiar with and like. They are not, however, restricted; they may delve deeply into federated data and query processing using their coding language. Blossom enables enterprise-wide collaboration so that users can work together on the same project and communicate much more effectively. The same data pipeline now looks like this:
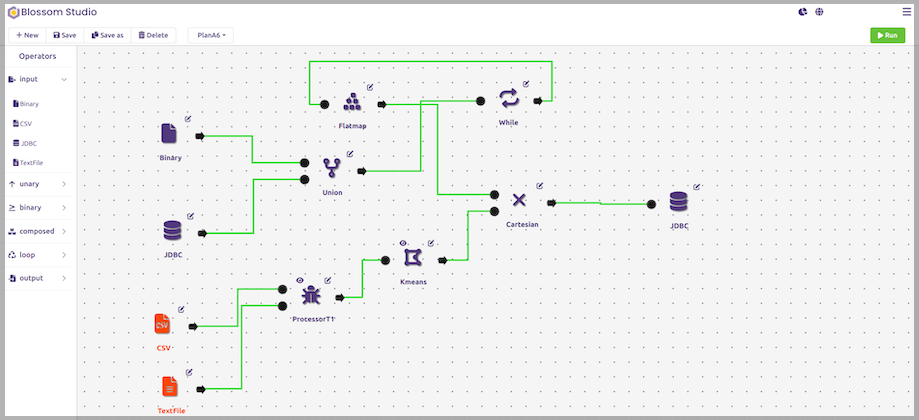
Conclusion
Smaller, but specialized models are AI models that are trained and fine-tuned on smaller amounts of data that are specific to a certain domain or task. Benefits of implementing small LLMs in enterprises and organizations include saving time and money, getting faster insights and allowing them to get better results from their models. Blossom Sky is a data accelerator that distributes queries across data processing infrastructures while reducing time to insight to minutes, and it enables users to easily build and train smaller, but specialized models for various domains and tasks over multiple data sources. It also supports simultaneous training of multiple LLMs on different, independent data sources, enabling users to create diverse and robust models by using the current data architecture.
With the help of Blossom Sky, organizations can easily manage their data in an efficient way and have access to the latest advancements in AI technology.
Links:
[2] (1) [D] GPT3 175B energy usage estimate. : MachineLearning (reddit.com)
About Scalytics
We enable you to make data-driven decisions in minutes, not days
Scalytics is powered by Apache Wayang, and we're proud to support the project. You can check out their public GitHub repo right here. If you're enjoying our software, show your love and support - a star ⭐ would mean a lot!
If you need professional support from our team of industry leading experts, you can always reach out to us via Slack or Email.







