Ready to transform your AI potential with data federation technology?
Data-driven decisions in minutes, not days.
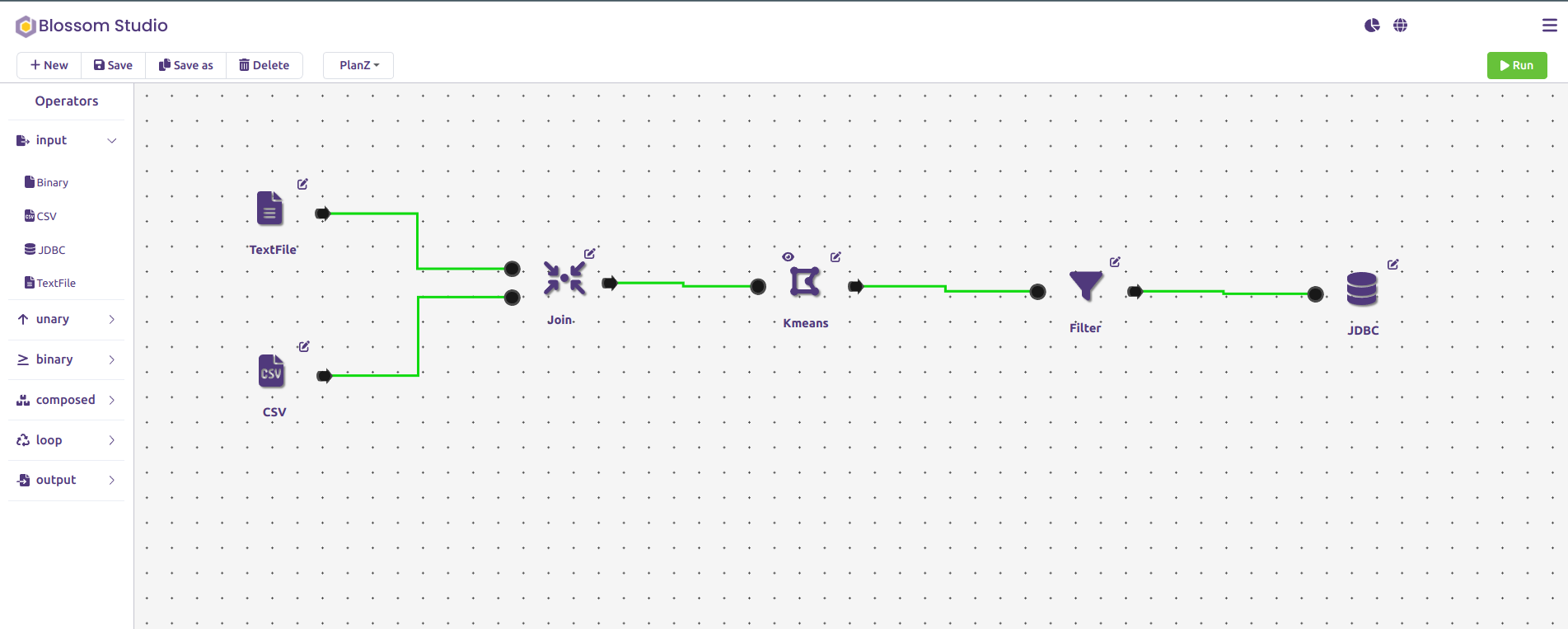
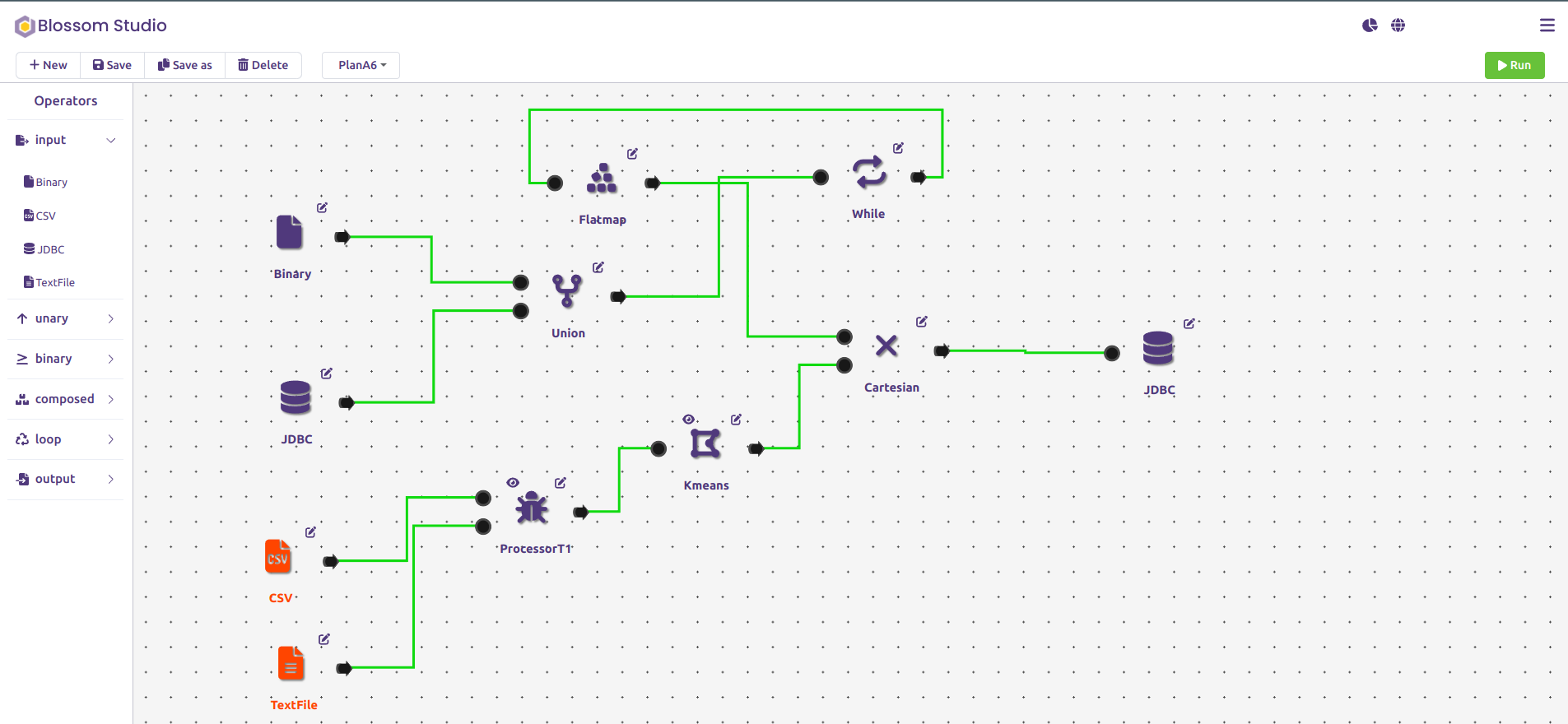
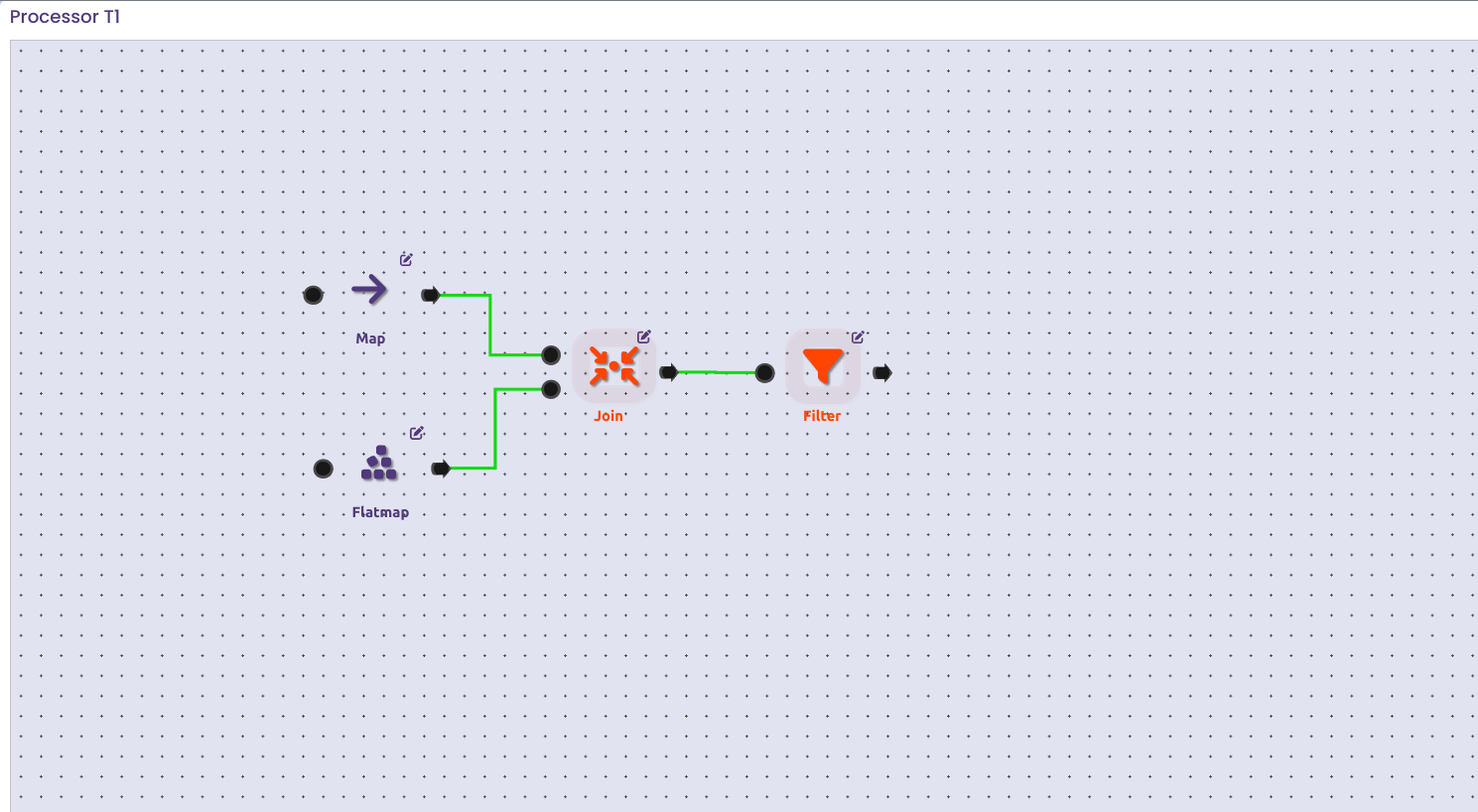
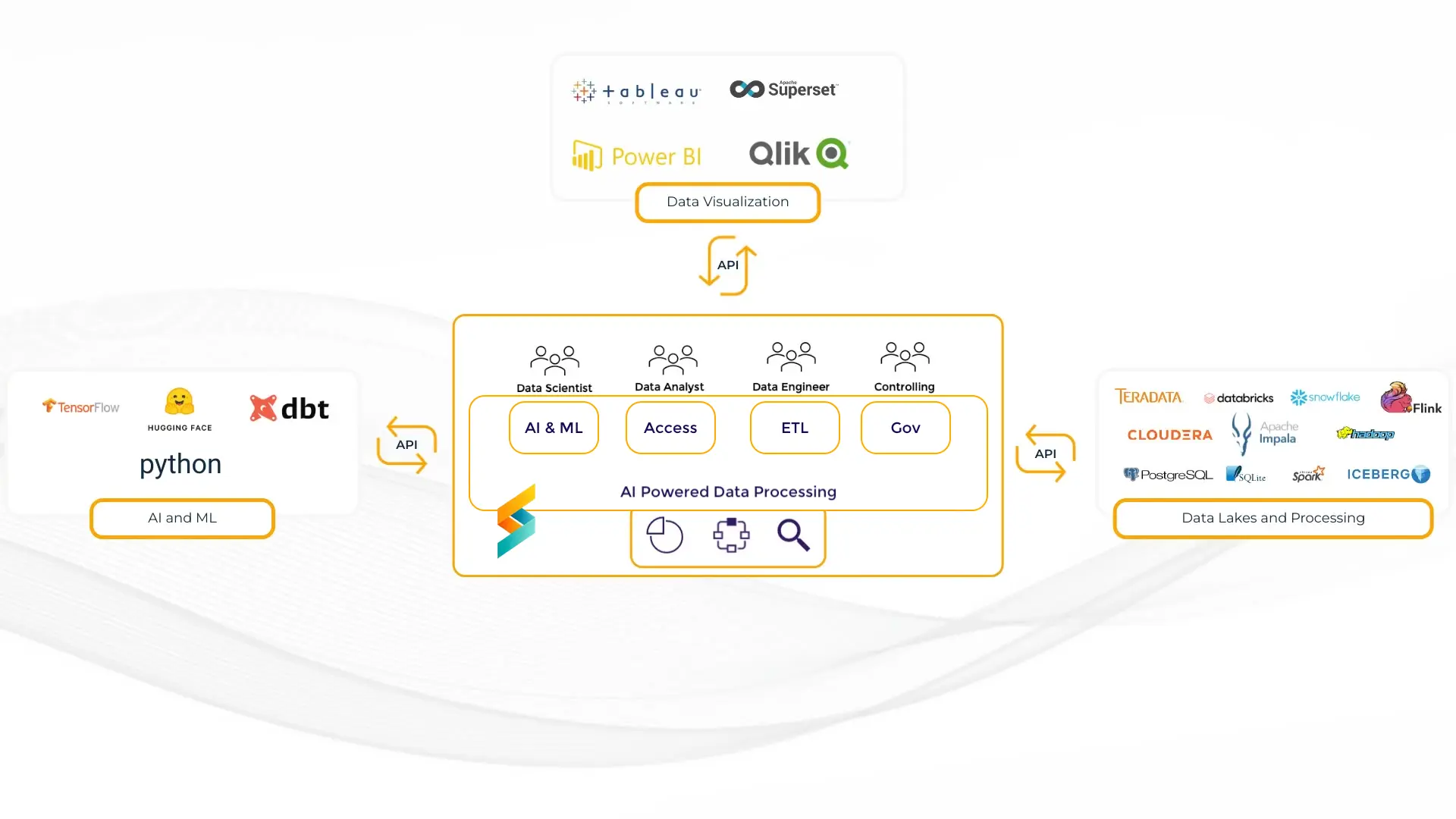
Scalytics Connect is the most scalable data architecture for AI. Push AI-driven growth in days, not months with our intelligent data processing optimizer. Simplify data integration and enable flexible data access, focus on building next-gen AI solutions. We take care about the rest.
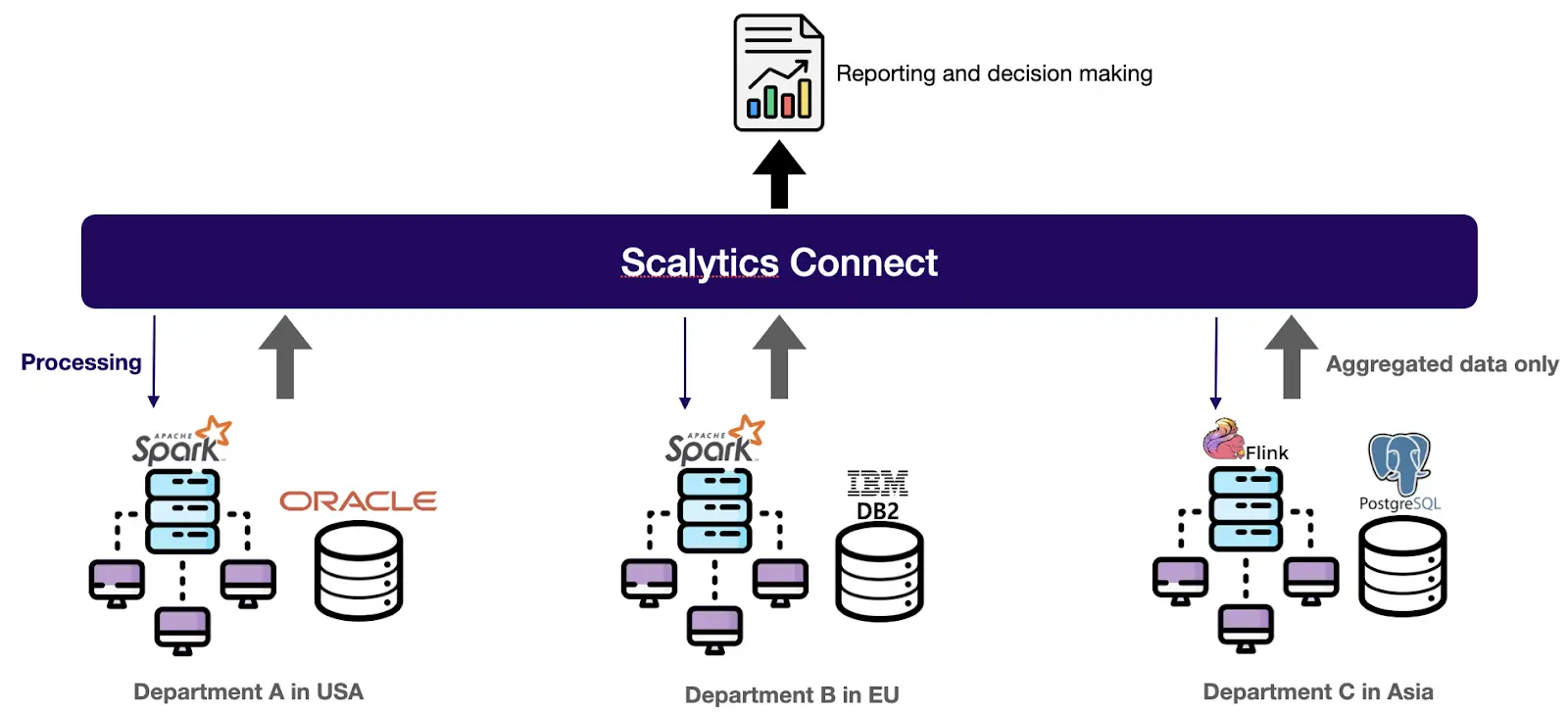
The Super API for AI: Integrate AI into your existing IT infrastructure and use previously unusable data files or legacy systems (like CRM, ERP, CAT, SCADA), specialized databases, edges, and even regulatory-protected data (HIPAA, GDPR, IPL) in the most secure and data privacy friendly way.
Virtual Data Layer: Ready for a unified AI fabric providing secure, localized access to all your information – cloud, on-premises, or disparate sources – in one platform? Imagine an AI data architecture and enable real-time AI-driven data optimization across your entire data network with our data federation technology.
Flexibility and Scalability Built-in: Scalytics Connect works with your existing infrastructure, be it cloud, on-premises, or a hybrid setup and enables real-time data processing with AI technology. Our platform is the most cost-effective AI data processing software, maximizing your ROI and data efficiency.
The Super API for AI: Integrate AI into your existing IT infrastructure and use previously unusable data files or legacy systems (like CRM, ERP, CAT, SCADA), specialized databases, edges, and even regulatory-protected data (HIPAA, GDPR, IPL) in the most secure and data privacy friendly way.
Virtual Data Layer: Ready for a unified AI fabric providing secure, localized access to all your information – cloud, on-premises, or disparate sources – in one platform? Imagine an AI data architecture and enable real-time AI-driven data optimization across your entire data network with our data federation technology.
Flexibility and Scalability Built-in: Scalytics Connect works with your existing infrastructure, be it cloud, on-premises, or a hybrid setup and enables real-time data processing with AI technology. Our platform is the most cost-effective AI data processing software, maximizing your ROI and data efficiency.
Scalytics Connect enables the best AI tools for data compliance and security in Healthcare, Energy, Retail, Industry Automation and Public Agencies. You need some inspiration? Explore real-world use cases, made with Scalytics Connect.