



Our big data analytics and federated learning engine, Scalytics Connect, is a powerful cross-platform middleware that can utilize and seamlessly integrate various execution platforms, including Postgres, Spark, Flink, Java Streams, and Python. In benchmarking, we found that Scalytics demonstrated exceptional performance across multiple use cases, including a popular machine learning algorithm, a core big data benchmark task, and a relational query. With Blossom, you can expect high-quality results and reliable performance across various platforms.
Scalytics Connect is based on Apache Wayang, an open source project with the goal of providing a platform to enable data-agnostic applications and decentralized data processing, the fundamentals of federated learning.
Dealing with Dispersed Data: Running a Relational Query Across Multiple Stores
In this use case, we address the common challenge of analyzing data stored in different systems, which is prevalent in many organizations. With our solution, companies and organizations can confidently perform analytics over relational data stored in multiple systems.
Datasets: To test the capabilities of our product, we utilized the trusted TPC-H benchmark [1], which comprises five datasets/relations. The lineitem and orders relations are stored in HDFS, while customer, supplier, and region are in Postgres, and nation is in S3 or the local file system. Our testing covered a range of dataset sizes, from 1GB to 100GB, to ensure our product's scalability and robustness.
Query/task: We evaluate the performance of the complex SQL TPC-H query 5:
Baselines: We compared Blossom with two widely-used systems for storing and querying relational data: Spark and Postgres. To conduct a fair comparison, we first moved all datasets to the system being tested (Spark or Postgres).
Results: The results of our tests, presented in Figure 1, show the execution time in seconds of the SQL query 5. Note that the time required to transfer data to Spark or Postgres was excluded from the results. As seen in Figure 1, Blossom significantly outperformed Postgres while retaining a runtime very close to Spark. However, it's important to note that for Spark to function, we needed twice the time to extract datasets from Postgres and transfer them to Spark. Blossom achieved such impressive performance by seamlessly combining Postgres with Spark: Blossom's query optimizer chose to perform all selections and projections on the data stored in Postgres before extracting data to join with the relations in HDFS. Additionally, the optimizer determined that executing the join between lineitem and supplier in Spark would be beneficial, as it could distribute the computational load of joining to multiple workers. All of this was done without the need for the user to specify where each operation should be executed. With Blossom, companies and organizations can expect a reliable and high-performing data analytics engine that seamlessly integrates multiple data systems.

Reducing Execution Costs for Machine Learning Tasks Using Multiple Systems
In this case study, we explore how Blossom can speed up runtime and reduce execution costs for machine learning tasks by leveraging multiple systems. In this case study, all data can be stored in a single store. In such cases, it often pays off to move parts of them to other faster engines depending on the workload. To test this feature, we use stochastic gradient descent, a very popular machine learning algorithm to perform classification.
Datasets: We use two real-world datasets that we downloaded from the UCI machine learning repository, namely higgs and rcv1. higgs consists of ~11 million data points with 28 features each and rcv1 contains ~677 thousand data points with ~47 thousand features each. In addition, we construct a synthetic dataset so that we can stress our product with even larger datasets, specifically with 88 million data points of 100 features each.
Query/task: We test the performance of training classification models for higgs and the synthetic dataset and a regression model rcv1. All three training models use stochastic gradient descent but with a different loss function. We use Hinge loss to simulate support vector machines for the classification tasks and the logistic loss for the regression task.
Baselines: We compare Blossom against MLlib from Apache Spark and SystemML from IBM, two very popular machine learning libraries.
Results: Our results, shown in Figure 2, demonstrate that Blossom outperforms both baselines by more than an order of magnitude in runtime performance for large datasets. In fact, Spark and SystemML could not even complete the training task for the synthetic dataset.

The key to Blossom's success is its optimizer, which spots that by utilizing a hybrid of Spark and local Java execution for the stochastic gradient descent descent algorithm it decreases the total execution time significantly. The datasets are preprocessed and prepared using Spark, while after the sampling phase of gradient descent the data points used for computing the gradient compose a very small dataset that is beneficial to process in a single machine using Java. This optimization is not easily noticeable without specialized and highly experienced engineers, but Blossom can achieve it without requiring any expertise from users.
Optimizing Big Data Analytics by Adapting Platforms to Data and Task Characteristics
In this case study, we explore how Blossom optimizes analytical tasks by adapting platforms based on data and task characteristics. Our approach involves changing platforms depending on the type of data and task at hand, which allows us to improve performance and efficiency. This case study demonstrates the potential of Blossom's platform adaptation for optimizing big data analytics.
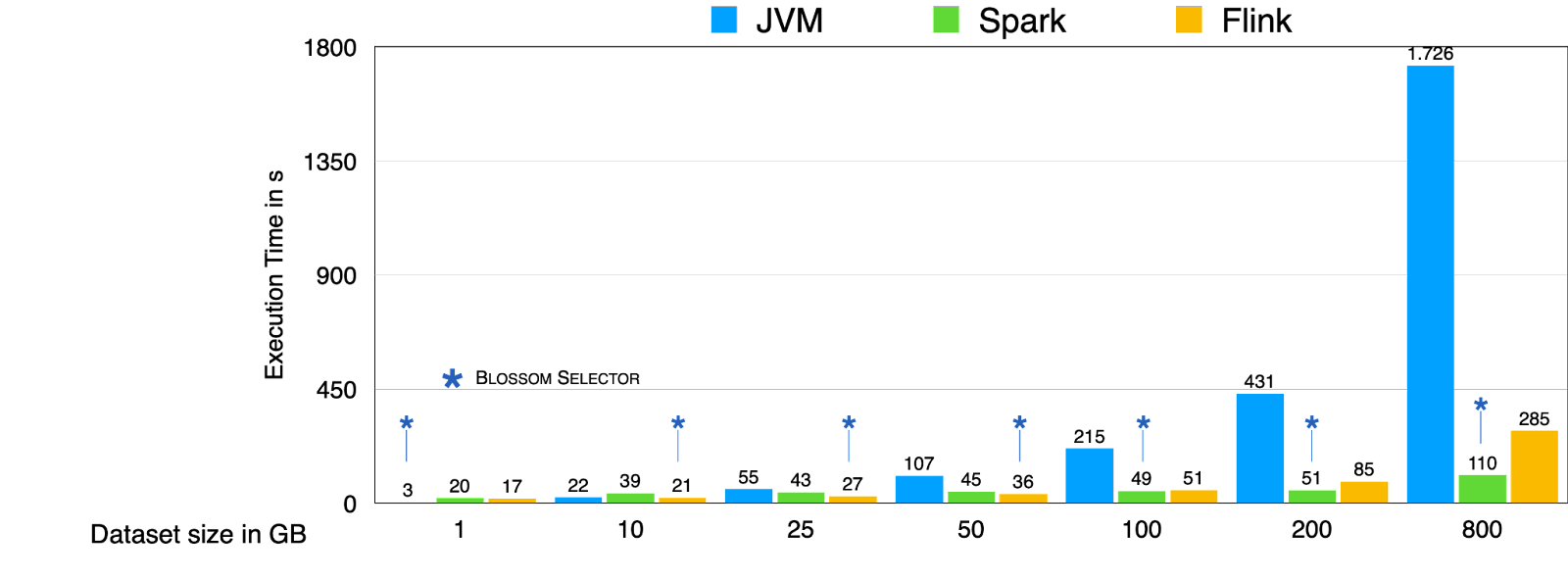
Datasets: We use Wikipedia abstracts and store them in HDFS. We vary the dataset size from 1GB to 800GB.
Query/task: We test our product with a widely popular big data analytical task, namely WordCount. It counts the number of distinct words in a text corpus. Different variations of wordcount are useful in various text mining applications, such as term frequency, word clouds, etc.
Baselines: We use three different platforms where Wordcount can be executed: Apache Spark, Apache Flink, and a single node Java program. We then set Blossom to be able to automatically choose which of the three platforms to use for each dataset.
Results: Our results, shown in Figure 3, demonstrate the effectiveness of Blossom's platform adaptation in choosing the fastest available platform for any dataset size in our WordCount case study. By modeling the cost of execution inside the query optimizer, Blossom eliminates the need for users to manually select a platform for their application, or migrate from one platform to another to gain performance and minimize costs. With Blossom, users can focus on their analytical tasks while our platform adaptation feature takes care of selecting the optimal platform for each query or task based on data and query characteristics. This results in faster execution and improved efficiency in big data analytics.
Summary
Scalytics Connect is a revolutionary big data analytics and federated learning engine that seamlessly integrates with various execution platforms. With exceptional performance in benchmarking tests and the ability to analyze dispersed data stored in different systems, Blossom is the ultimate solution for companies looking to optimize their data analysis. Tested using the TPC-H benchmark and showing unparalleled scalability and robustness when compared with Spark and Postgres, Blossom is a game-changer for data executives looking to stay ahead of the curve.
[1] TPC-H Homepage
About Scalytics
We enable you to make data-driven decisions in minutes, not days
Scalytics is powered by Apache Wayang, and we're proud to support the project. You can check out their public GitHub repo right here. If you're enjoying our software, show your love and support - a star ⭐ would mean a lot!
If you need professional support from our team of industry leading experts, you can always reach out to us via Slack or Email.







